 Wassim Almaaoui
Wassim Almaaoui
1 min read
From Holiday Highs to Lasting Loyalty: Strategies That Endure
Turn seasonal spikes into long-term loyalty. Explore strategies retailers can use to maintain momentum & deepen customer relationships beyond peak periods.
AI Personalization Science→
Unlock the full value of your customer data with AI you can trust, built for retailers to deliver personalization at scale
Real-Time Loyalty→
Build lasting loyalty with a proven engine trusted by leading omnichannel retailers
Omnichannel Promotions→
Drive growth where it counts with the most flexible promotions platform in retail
Smart Checkout→
Create moments your customers remember by delivering the right offer at the right time, every time
Gifting & Top-Up→
Turn gifting into loyalty with seamless digital gift cards and self top-ups across every channel
PromoBase→
Eliminate coupon fraud from your business for good with the smarter way to validate, redeem and settle CPG coupons
Built to partner at scale
Working with technology, solution, and integration partners to help retailers deliver smarter loyalty and personalization.



At Eagle AI, data isn’t just part of our business, it is our business. Our mission is simple but ambitious: build the right promotion for the right customer and tune every parameter, like trigger amount, reward, brand, and this, in a 100% individualized way, all based on purchase history.
So, yeah… data processing isn’t a support function here. It’s the core engine behind everything we do.
When we first built our data platform, Spark (via Dataproc) was the hot thing.
It was the technology everyone in the data world was excited about: powerful, distributed, and super hype at the time.
And for us, it made perfect sense:
It was the perfect choice for a data-driven startup back then: modern, scalable, and expressive.
BigQuery wasn’t new but around 2021, we started experimenting with it seriously, and quickly realized its power:
It felt like the future: simple, fast, and cloud-native.

At some point, we took a major step on the storage side:
we decided to migrate all our data from GCS to BigQuery, a no-brainer for us (and worth its own article 👀).
From that point on, BigQuery became our main data layer, not just a warehouse but the backbone where all our raw and processed data lives.
Now, when it comes to processing, which is what this article is really about, the choice isn’t that obvious.
Even though all our data sits in BigQuery, we still have two ways to process it:
And that's where the debate really began.
We gathered the whole data team to decide between two options:
- Option 1: Stay with Spark: flexible, proven, and part of our DNA.
- Option 2: Go all-in on BigQuery: simpler, faster, and cloud-native.
We debated a lot. Each side had solid arguments.
And in the end… we didn’t pick one.
We picked both.
Here’s a visual overview of some key milestones in the evolution of Eagle AI’s data stack, highlighted by the introduction of BigQuery into a setup historically built around Spark and GCS.
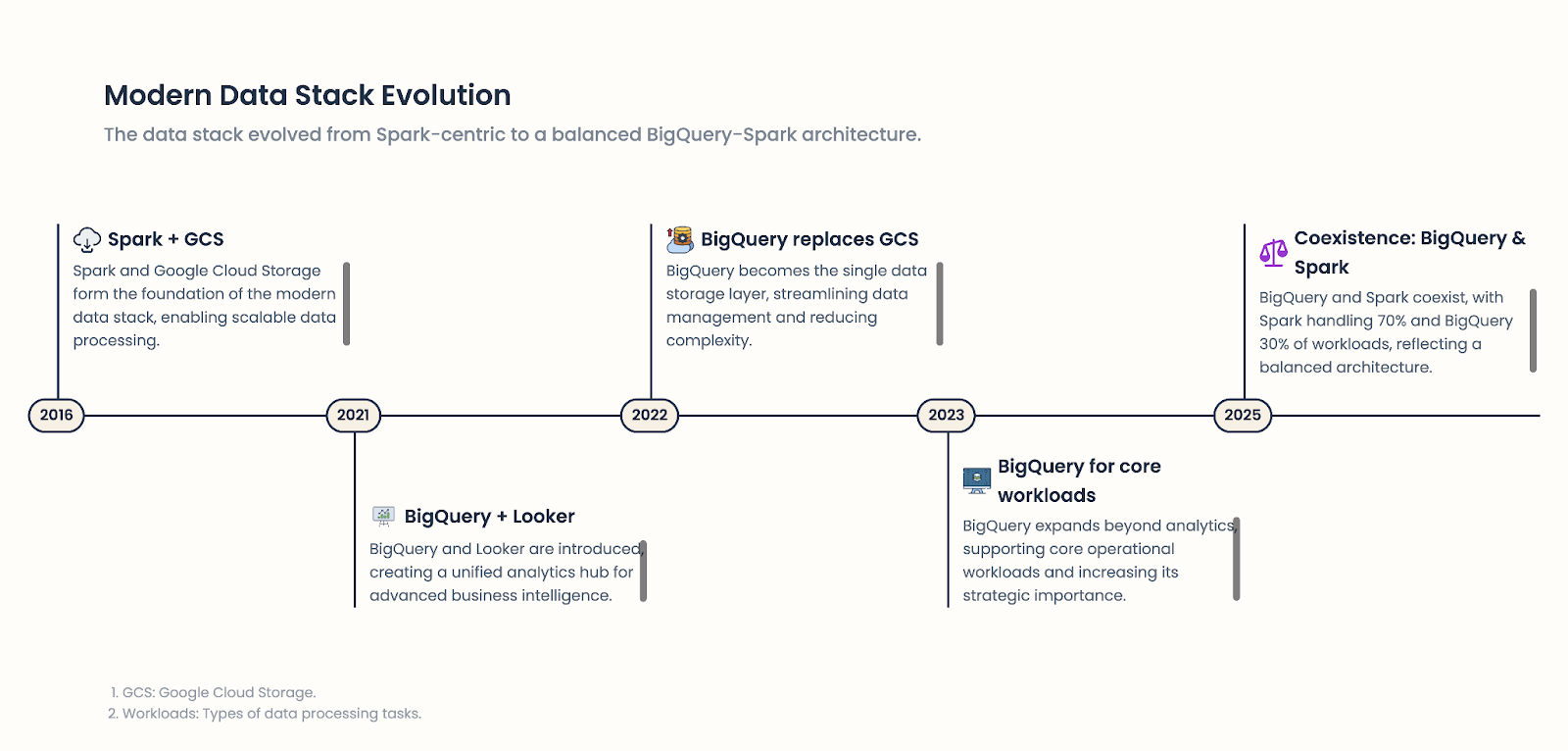
We decided to keep both frameworks, because they can actually be seen as complementary tools, as long as you choose the right one for each job.
That last part turned out to be the real challenge: making sure everyone (including newcomers) knew which tool to use when.
So we created a simple internal guide to help with that.
Use BigQuery when:
It’s mainly SQL analytics or transformations (joins, group bys, aggregations).
Performance matters (big tables, short runtime).
You’re doing exploration or debugging (query directly in the GCP console).
Use Spark when:
It’s ML, streaming, or custom logic (API calls, Slack notifications, SFTP...).
The job has complex business rules: code is clearer and easier to test.
The job involves multiple logic paths or implementations, these are easier to manage with interfaces, inheritance, and structured control flow (if/else, pattern matching, etc.)
It’s an extension of an existing Spark job: reuse logic instead of rewriting it.
To make it more concrete, here are two examples from our daily jobs that perfectly illustrate this balance. One where BigQuery clearly is much faster, and another where Spark coding makes development and readability easier.
Let’s take a concrete case. We wanted to aggregate a few sales KPIs by customer segment after joining three tables (sales, customer, and segment).
In total, the query scans around 200 GB of data.
SELECT
segment.segment_id,
COUNT(DISTINCT sales.customer_id) AS total_customers,
COUNT(DISTINCT sales.trx_id) AS total_transactions,
SUM(sales.amount) AS total_ca,
APPROX_QUANTILES(sales.amount, 100)[OFFSET(90)] AS p90_transaction_amount
FROM
`sales` AS sales
INNER JOIN
`customer` AS customer USING(customer_id)
INNER JOIN
`segment` AS segment USING(customer_id)
WHERE
day >= "2024–09–01"
GROUP BY 1;
We ran the exact same job on Spark (with a reasonably large cluster) and BigQuery.
Here’s how they compared:
|
Metric |
Spark (8 workers × 8 CPU / 64 GB RAM each) |
BigQuery |
|
Runtime |
~1h45 min |
⚡ 2 min |
|
Cost |
~$6.80 |
~$1.20 |
|
Maintenance |
Cluster setup & tuning |
None (serverless) |
For pure analytical workloads, BigQuery simply crushed it, (much) faster, cheaper, and effortless.

The maintenance part is non-negligible: I had to test multiple Spark configurations to find the right worker type and parameters just to make the job succeed. This highlights how much optimization and babysitting BigQuery saves you.
From experience, Spark jobs need constant fine-tuning and revalidation after every code change. It’s easy to break optimizations or lineage if you’re not careful.
BigQuery, on the other hand, takes care of all that behind the scenes.
Now take a job that filters customer promotions based on multiple business rules:
Here’s how it looks in Scala/Spark:
val nbPromotions = 10
val reward =
val ds: Dataset[CustomerPromotions] =
spark.read.format("bigquery").load("project.dataset.customer_promotions")
.as[CustomerPromotions]
ds.map(x => x.customerId -> selectBestPromotions(x.promotions, nbPromotions))
def selectBestPromotions(promotions: Seq[Promotion], nbPromotions: Int) = {
val sortedPromotions = promotions.sortBy(_.rank)
val nationalPromotions = sortedPromotions.filter(_.scope == National).take(3)
val brandsInNationalPromotions = nationalPromotions.map(_.brand_id).toSet
val regionalPromotions = sortedPromotions
.filter(_.scope == Regional)
.filter(promo => !brandsInNationalPromotions.contains(promo.brand_id))
.take(nbPromotions - nationalPromotions.length)
nationalPromotions ++ regionalPromotions
}
And here’s the same logic in BigQuery SQL
DECLARE nb_promotions INT64 DEFAULT 10;
WITH nat AS (
- Top-3 National per customer ranked
SELECT
cp.customer_id,
(SELECT ARRAY_AGG(n ORDER BY n.rank LIMIT 3)
FROM UNNEST(cp.promotions) AS n
WHERE n.scope = 'National') AS nat
FROM `project.dataset.customer_promotions` AS cp
)
SELECT
cp.customer_id,
ARRAY_CONCAT(
COALESCE(n.nat, []),
(
- Complete with Regional, exclude Brands in National
SELECT ARRAY_AGG(r ORDER BY r.rank
LIMIT GREATEST(@nb_promotions - ARRAY_LENGTH(COALESCE(n.nat, [])), 0))
FROM UNNEST(cp.promotions) AS r
WHERE r.scope = 'Regional'
AND NOT EXISTS (
SELECT 1 FROM UNNEST(IFNULL(n.nat, [])) AS nn
WHERE nn.brand_id = r.brand_id
)
)
) AS promotions
FROM `project.dataset.customer_promotions` AS cp
LEFT JOIN nat AS n
USING (customer_id);
The result is the same, but the Spark code is clearer, easier to maintain, and simpler to test, as the main business logic is divided into well-named functions that outline each step clearly.
Once the logic becomes more complex, Spark provides better readability and flexibility.
At Eagle AI, we’ve stopped thinking in terms of Spark vs BigQuery.
Instead, we ask:
“Which one makes this job simpler, faster, and easier to maintain?”
Sometimes that’s BigQuery, especially for analytics and transformations.
Sometimes it’s Spark, for jobs with richer business logic or external integrations.
And sometimes, you can even combine both worlds in a single job.
For example, we might start with a heavy SQL transformation directly on BigQuery, something like:
val ds = spark.read.option("query", "SELECT * FROM … JOIN … GROUP BY …").load()
Then, once the data is pre-aggregated and ready, we switch to Spark to apply the more complex, business-specific logic or make external API calls.
This approach lets BigQuery handle the heavy lifting, while Spark focuses on the parts that are harder to express in SQL.
Because the best data platform isn’t about choosing sides, it’s about choosing wisely.

1 min read
Turn seasonal spikes into long-term loyalty. Explore strategies retailers can use to maintain momentum & deepen customer relationships beyond peak periods.

5 min read
Discover how EagleAI reduced Google Cloud Storage costs by 50% using lifecycle rules, automation, and better monitoring across projects.

7 min read
Discover how to choose the right loyalty solutions for retail. Explore core features, industry challenges, and why Eagle Eye delivers unmatched expertise.